Event Driven na Convenia
Olá pessoal, event driven é uma arquitetura muito difundida em microserviços por promover desacoplamento entre os diferentes serviços, na Convenia fizemos a opção por essa arquitetura e nesse artigo gostaria de expor um pouco do que fizemos e como fizemos.
Primeiramente gostaria de dizer que as escolhas que fizemos foram levando em consideração nossa escala e previsão de crescimento, essa stack pode não ser a ideal para você e por se tratar de um tema bem amplo e sem uma definição formal, tomamos algumas iniciativas que fazem muito sentido para nós, mas podem não se encaixar bem no seu case, apesar disso é provável que o texto a seguir seja construtivo caso você esteja pensando em fazer algo assíncrono a desacoplado.
Como funciona uma arquitetura guiada por eventos?
Todo framework maduro atualmente vem com algum tipo de event bus, se você está familiarizado com esse conceito basta pensar nisso de uma forma mais ampla, ao invés de haver uma classe que dispara um evento e N classes de Listeners que ouvem esse evento, teriamos um serviço emissor e N serviços "ouvintes", caso isso não tenha ajudado na compreensão vou explicar um pouco melhor:
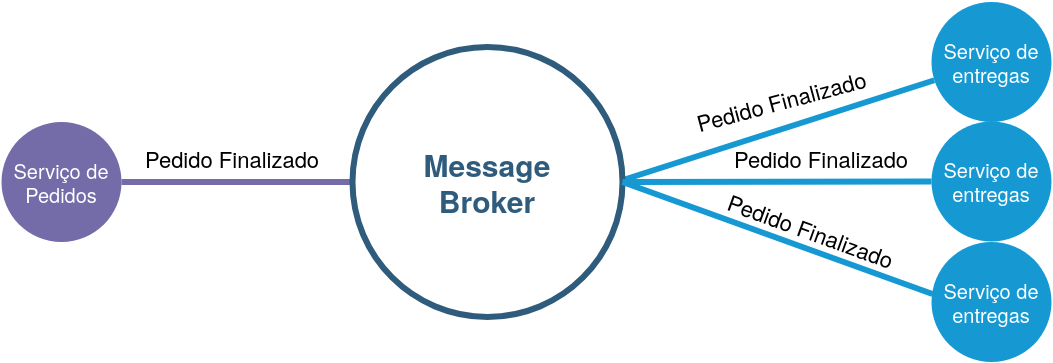
Na imagem acima temos alguns elementos importantes:
-
Serviço emissor (Serviço de pedidos): é o serviço de onde o estimulo é originado, ele é responsável apenas por fechar o pedido e ao finalizar ele grita: "Pedido Finalizado"! Dessa forma todos os outros serviços que se importam por esse "estimulo" podem reagir a ele. O serviço emissor não conhece os serviços que "se importam" pela mensagem dele, a atuação dele acaba integralmente após a emissão da mensagem.
-
Serviços Ouvintes (representados à direita da figura): Os três serviços se importam pela mensagem emitida pelo serviço de pedidos mas não conhecem o serviço de pedidos em si, dai para frente eles podem fazer o que quiserem com a mensagem emitida sem influenciar o serviço emissor ou mesmo sem influenciar outros ouvintes, muito diferente do que aconteceria em uma abordagem procedural.
-
Message broker(a peça central): Esse elemento é o responsável por promover o desacoplamento temporal entre o emissor e os ouvintes, isso significa que a mensagem é emitidas quando o emissor acha conveniente e sem que ele se importe se os ouvintes vão poder ouvir a mensagem naquele momento, os ouvintes podem ouvir a mensagem quando eles quiserem, se caso um ouvinte está offline ou mesmo "quebrado", o message broker vai "segurar" a mensagem até que aquele ouvinte esteja apto a recebe lá.
Como isso tudo se encaixa no ecossistema da Convenia?
Ao escolher as peças da stack procuramos manter o mínimo de complexidade possível para que a stack não nos onere e para que o desenvolvimento permaneça simples, fizemos a opção pelo rabbitmq pela simplicidade de uso e setup e por ser uma opção robusta o bastante.
Do lado das aplicações utilizamos PHP com o framework Laravel e isso nos trouxe bastante agilidade no desenlvolvimento das aplicações, porém quase não existem soluções para fazer todos os serviços funcionarem como uma unidade, então fizemos muita coisa por conta própria.
Logo no inicio começamos a fazer a comunicação entre os serviços com a lib mais difundida de php, a amqplib, que apesar de cumprir o seu papel e ser performática o bastante, parece desajeitada e é praticamente imockavel(intestável), além de nos obrigar a escrever um boilerplate deselegante, para resolver esse problema escrevemos o Pigeon(sugiro a leitura da documentação), ele envelopa a amqplib nos dando a possibilidade de testar as emissões e escrever um código verdadeiramente elegante, o Pigeon também nos permite tratar o rabbitmq como descartável, ao invés de manter um arquivo de definição de filas versionado, o Pigeon é capaz de criar as filas on the fly e já fazer os binds corretamente, se algo der errado apenas subimos outra instancia do rabbit e tudo irá funcionar.
Aqui está um exemplo de emissão de um evento com o Pigeon:
Pigeon::dispatch('sample.event', [
'scooby' => 'doo'
]);Para ouvir o evento acima poderíamos fazer o seguinte código:
Pigeon::events('sample.event')
->callback(
Closure::fromCallable([$this, 'httpCallback'])
)->fallback(
Closure::fromCallable([$this, 'httpFallback'])
)->consume(0, true);No exemplo acima definimos uma Closure para um callback(quando tudo ocorre bem) e outra para um fallback(quando algo da errado), o Pigeon é bem completo e pretendo entrar em mais detalhes em um outro post, mas por hora acredito que isso demonstra bem como ocorrem a comunicação entre os serviços.
Como projetar um Listener?
O listener é a classe que vai conter o código que ouve os eventos(código apresentado no item anterior), esse código abre um soquet com o rabbitmq e fica esperando por eventos, isso significa que o processo do listener nunca vai "morrer", por isso precisamos tomar alguns cuidados especiais pois por padrão o programador PHP está acostumado com o ciclo de vida do request, que é bem efêmero e isso nos permite fazer algumas transgressões que quando cometidas em um Listener pode dar muita dor de cabeça, seguem alguns cuidados necessários.
-
Execute o listener sempre sobre o supervisor: Isso não é só aconselhado para programas escritos em PHP, o vault é uma ferramenta para gerenciar segredos escrita em go e é aconselhável rodar ele sobre o supervisor também, isso porque o supervisor pode reviver o seu processo caso ele morra, sem ele seu listener morreria e você precisaria fazer um processo manual para revive-lo e com listener morto o serviço está "surdo".
-
Configure corretamente o supervisor: é importante dar atenção para as configurações do supervisor relacionadas a tentativas, em casos extremos o supervisor fica tentando reiniciar o processo que está quebrado infinitamente causando alto consumo de CPU, em setups mais simples onde o webserver fica na mesma instancia do Listener isso seria catastrófico pois o próprio webserver seria impactado, pense que se você utiliza algum serviço para gerenciar exceções como o sentry, normalmente existe uma cota, você pode estourar essa cota com as infinitas tentativas do supervisor e perder visibilidade.
-
Separe as instancias de listeners das instancias de webserver: para evitar a situação do item anterior seria uma boa prática ter instancias de "Worker", que rodam apenas esse listener, essas instancias tendem a ser mais simples também pois não precisam ser acessadas via HTTP, em clouds como a aws isso economizaria o custo e esforço de setup com load balancer.
-
Evite desperdiçar recursos: Agora o processo se mantêm vivo por muito tempo então devemos tomar o cuidado de fechar as conexões que abrimos e não fazer nem um tipo de procedimento que pode se acumular durando o consumos das mensagens do rabbitmq, suponha que você copie uma imagem para redimensiona-la e esquece de apagar essa imagem no final do processo, logo logo você ficará sem armazenamento, o mesmo é muito comum de acontecer com uso de memória.
-
Comandos do artisan: Comandos do artisan são feitos para procedimentos pontuais, coisas efêmeras também e não para "long running tasks", apesar da transgressão conceitual eles são uma opção de estrutura para fazer um listener, dentro dele você terá acesso a todas as estruturas do Laravel, apenas tenha em mente que comandos do artisan consomem um tando de memória considerável.
-
Idempotência: As mensagens podem ser reenviadas, logo a mesma mensagem pode chegar no mesmo listener 2 vezes, seu listener precisa processar essa mensagem de forma Idempotente, imagine que ele crie um registro no banco com um id "auto increment", se a mensagem chegar novamente ele não pode criar um outro registro, talvez um upsert seria a saída nesse caso.
-
Rejeite a mensagem em caso de falha: isso vamos explicar no próximo item...
E quando as coisas dão errado?
Certamente em algum momento as coisas vão quebrar, o listener quebrado tenta reprocessar a mensagem o número de vezes que foi estipulado pela configuração do supervisor e depois vai morrer, nesse caso a mensagem ficará represada na fila até o listener ser corrigido, após o deploy da correção a mensagem é consumida corretamente e tudo volta ao normal.
A situação acima não é a ideal pois o listener muitas vezes morre apenas para uma determinada mensagem, o rabbitmq tem uma configuração de dead letter exchange que nos permite enviar a mensagem para um local específico em caso de falha, no nosso caso rejeitamos todas as mensagem que causaram alguma falha.
Agora recebemos todas as mensagens quebradas em um único lugar mas deveríamos dar mais visibilidade possibilidades para essas mensagens, então criamos o LetterThief(Ladrão de cartas), um serviço que tem como objetivo notificar toda a falha e nos dá a possibilidade de reenviar as mensagens que causaram essa falha.
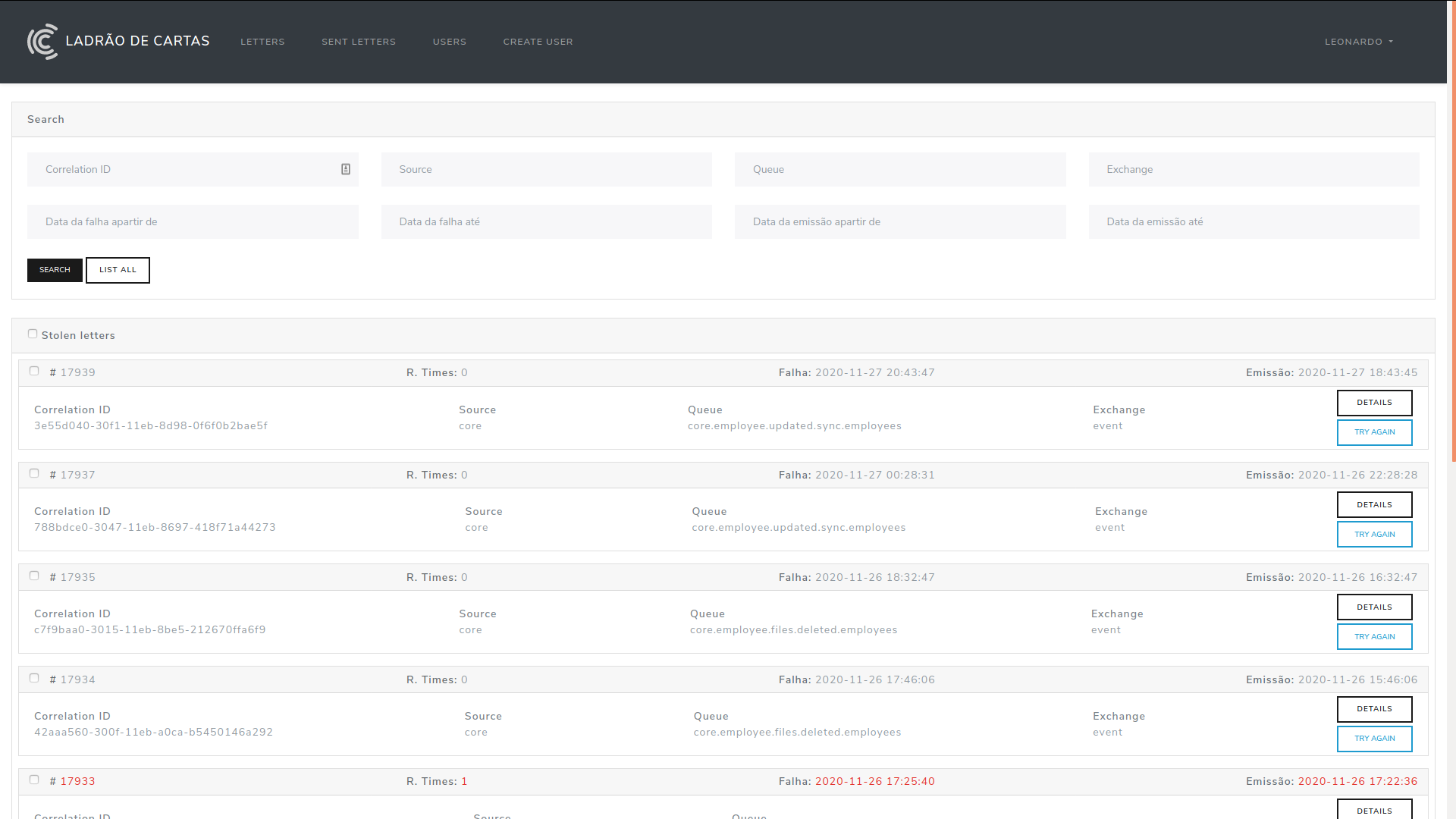
A imagem acima mostra a interface do Ladrão, com algumas ações com destaque para a ação "Try again", esse botão nos dá a possibilidade de reenviar a mensagem para o serviço de onde ela foi originada.
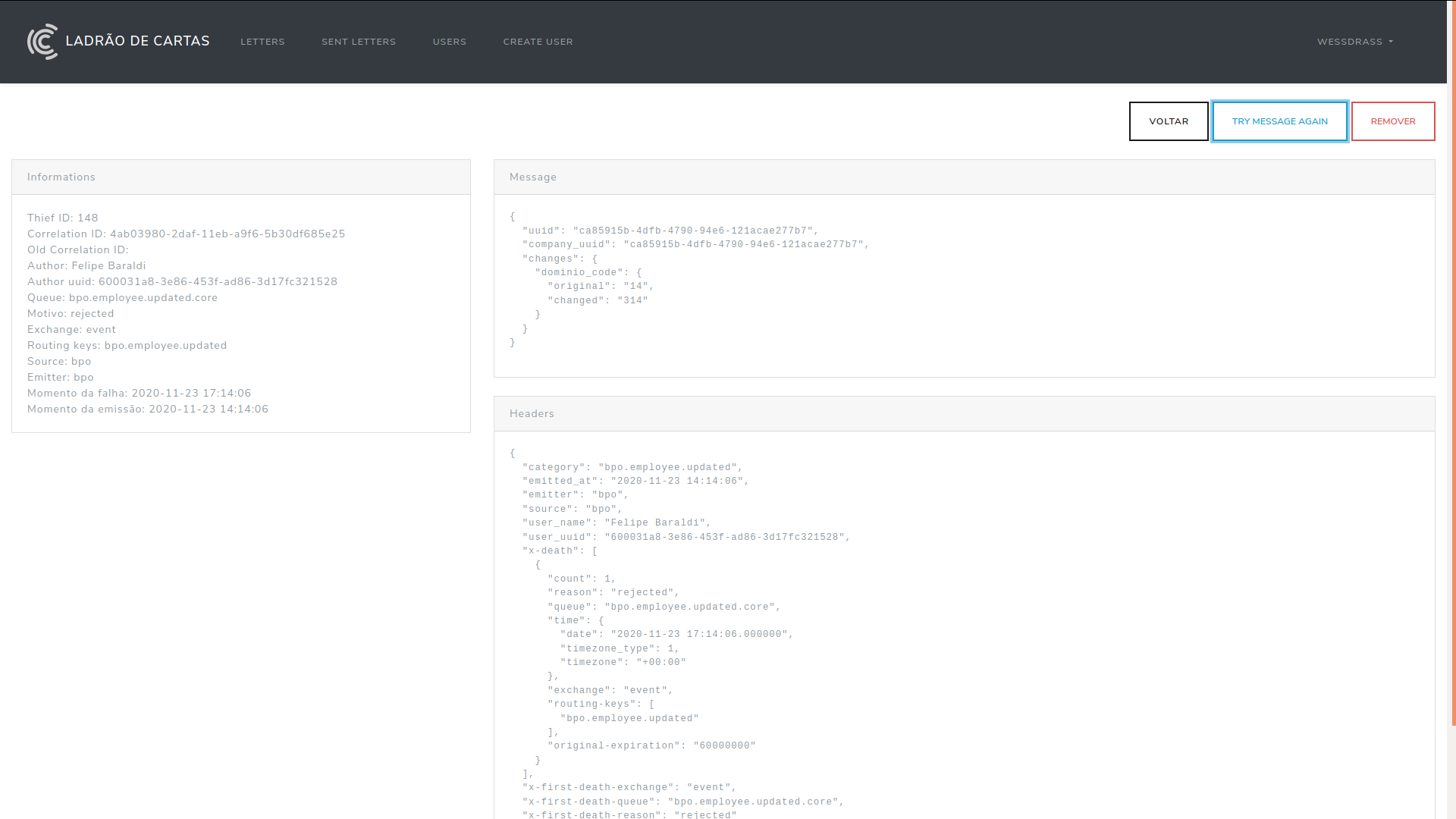
Ao abrir uma mensagem temos várias informações como metadados, headers e body, isso vai nos permitir reproduzir e corrigir o erro em ambiente local, somente após o deploy do fix devemos reenviar a mensagem.
Somente represar erros em um lugar específico não adiante, temos que soar um alarme avisando esse erro, no nosso caso temos um canal do slack onde caem todos os erros, a figura a sseguir mostra como isso funciona:

Ao ver a notificação no slack sabemos qual desenvolvedor é responsável para corrigir a falha justamente pelo nome da fila, esse desenvolvedor focará imediatamente nesse fix.
Conclusão
Toda arquitetura distribuída será relativamente mais complexa que um serviço em um único repositório, mas acredito que conseguimos chegar em uma arquitetura relativamente simples e segura, se comparado com o padrão utilizado em microserviços no mercado, cada case tem uma necessidade específica então dificilmente isso funcionará completamente para você mas pode ser que você tire alguma ideia disso tudo, e principalmente, jamais distribua sua arquitetura se não for realmente necessário.
Espero ter contribuído de alguma forma....
···
